ADD A[R0], @B;
ANSWER : 6
A TOTAL OF 6 MEMORY ADDRESS NEED TO BE ACCESSED TIN ORDER TO PERFORM THE INSTRUCTION.
THE ABOVE CODE CONTAINS 3 PARTS:
1. DISPLACEMENT ADDRESSING A[R0]
2. INDIRECT ADDRESSING @B
3. ARITHMETIC OPERATION / STORE RESULT ADD
1. A[R0] RESULTS IN 3 MEMORY ACCESS
EFFECTIVE ADDRESS IS CALCULATED AS
A[R0] = A + (R0)
A[R0] IS A TYPE OF DISPLACEMENT ADDRESSING MODE IN WHICH THE FINAL MEMORY [A+R0] IS ACCESSED BY ADDING THE BASE ADDRESS "R0" TO THE DISPLACEMENT ADDRESS "A"

2. @B FETCHED THE OPERAND IN 2 MEMORY ACCESS SINCE IT IS AN INDIRECT ADDRESSING MODE.
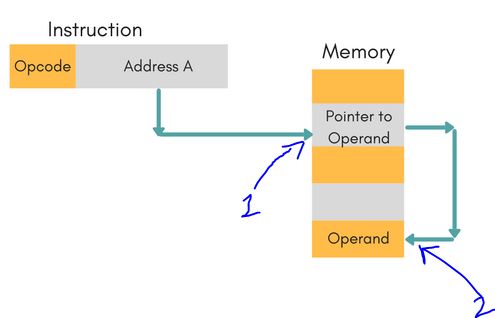
3. ONE MORE MEMORY ACCESS IS REQUIRED IN ORDER TO STORE THE FINAL ADD RESULT IN THE DESTINATION ADDRESS.
A TOTAL OF 6 MEMORY ADDRESS NEED TO BE ACCESSED TIN ORDER TO PERFORM THE INSTRUCTION.