${\color{Blue} 5} $ ${\color{Blue} most} $ ${\color{Blue}expensive } $ ${\color{Blue}books } $
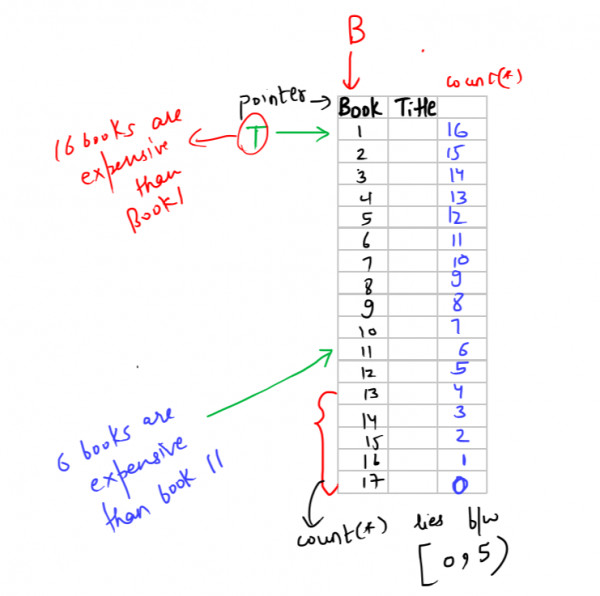
Just make a random table, and then, use two pointers T and B, now, just iterate the T pointer for each of B pointer
You will realise, this is like a nested for loop implementation.
This property is the soul of nested sub queries
You have to take example and solve
Now How easy it becomes
Thanks
Shashank